
0ld IRC Bots
Very old IRC Bots not being updated and put in archives.
These IRC Bots range from windows to all different types of OS and Pearl to GNU
17 files
-

irclogger
This is an IRC logger with a webinterface. To install, create a new MySQL table using the provided 'mysql.sql' script and edit the 'irclog.config.php' to match your database and IRC channel settings. Then run the 'irclog.pl -s' script to start logging. The logger needs the following perl modules: POE::Component::IRC Digest::MD5 DBI::mysql0 downloads
(0 reviews)0 comments
Submitted
-

irc-rss-feed-bot
irc-rss-feed-bot
irc-rss-feed-bot is a dockerized Python 3.11 and IRC based RSS/Atom and scraped HTML/JSON/CSV feed posting bot. It essentially posts the entries of feeds in IRC channels, one entry per message. More specifically, it posts the titles and shortened URLs of entries.
Contents
Features Links Examples Development Usage Configuration: secret Configuration: non-secret Global settings Mandatory Recommended Developer Feed-specific settings Mandatory Optional Parser Conditional Feed default settings Commands Administrative Deployment Maintenance Service Config Database Disk cache Features
Multiple channels on an IRC server are supported, with each channel having its own set of feeds. For use with multiple servers, a separate instance of the bot process can be run for each server. Entries are posted only if the channel has not had any conversation for a certain minimum amount of time, thereby avoiding the interruption of any preexisting conversations. This amount of time is 15 minutes for any feed which has a polling period greater than 12 minutes. There is however no delay for any feed which has a polling period less than or equal to 12 minutes as such a feed is considered urgent. A SQLite database file records hashes of the entries that have been posted, thereby preventing them from being reposted. Posted URLs are shortened using the da.gd service. The hext, jmespath, and pandas DSLs are supported for flexibly parsing arbitrary HTML, JSON, and CSV content respectively. These parsers also support configurable recursive crawling. Entry titles are formatted for neatness. Any HTML tags and excessive whitespace are stripped, all-caps are replaced, and excessively long titles are sanely truncated. A TTL and ETag based compressed disk cache of URL content is used for preventing unnecessary URL reads. Any websites with a mismatched strong ETag are probabilistically detected, and this caching is then disabled for them for the duration of the process. Note that this detection is skipped for a weak ETag. Encoded Google News and FeedBurner URLs are decoded. For several more features, see the customizable global and feed-specific settings, and commands.
Links
Caption Link Repo https://github.com/impredicative/irc-rss-feed-bot Changelog https://github.com/impredicative/irc-rss-feed-bot/releases Image https://hub.docker.com/r/ascensive/irc-rss-feed-bot Examples
<FeedBot> [ArXiv:cs.AI] Concurrent Meta Reinforcement Learning → https://arxiv.org/abs/1903.02710v1 <FeedBot> [ArXiv:cs.AI] Attack Graph Obfuscation → https://arxiv.org/abs/1903.02601v1 <FeedBot> [InfoWorld] What is a devops engineer? And how do you become one? → https://da.gd/dvXh9 <FeedBot> [InfoWorld] What is Jupyter Notebook? Data analysis made easier → https://da.gd/yrCi <FeedBot> [AWS:OpenData] COVID-19 Open Research Dataset (CORD-19): Full-text and metadata dataset of COVID-19 research articles. → https://registry.opendata.aws/cord-19
Development
For software development purposes only, the project can be set up on Ubuntu as below.
make setup-ppa make install-py make setup-venv make shell make install make test make build Usage
Configuration: secret
Prepare a private secrets.env environment file using the sample below.
IRC_PASSWORD=YourActualPassword GITHUB_TOKEN=c81a62ca23caa140715bbfc175997c02d0fdd768 GITHUB_TOKEN
This is optional. Refer to the publish.github feature.
Configuration: non-secret
Prepare a version-controlled config.yaml file using the sample below. A full-fledged real-world example is also available.
host: irc.libera.chat ssl_port: 6697 #ssl_verify: true nick: MyFeedBot admin: mynick!myident@myhost alerts_channel: '#mybot-alerts' mode: #mirror: '#mybot-mirror' #publish: # github: MyGithubServiceAccountUsername/IrcServerName-MyBotName-live #defaults: # new: all feeds: "##mybot-alerts": irc-rss-feed-bot: url: https://github.com/impredicative/irc-rss-feed-bot/releases.atom period: 12 shorten: false "#some_chan1": AWS:OpenData: url: https://registry.opendata.aws/rss.xml message: summary: true CDC:FoodSafety: url: https://tools.cdc.gov/api/v2/resources/media/316422.rss redirect: true j:AJCN: url: https://academic.oup.com/rss/site_6122/3981.xml mirror: false period: 12 blacklist: title: - ^Calendar\ of\ Events$ LitCovid: url: https://www.ncbi.nlm.nih.gov/research/coronavirus-api/export pandas: |- read_csv(file, comment="#", sep="\t") \ .assign(link=lambda r: "https://pubmed.ncbi.nlm.nih.gov/" + r["pmid"].astype("str")) \ .convert_dtypes() MedicalXpress:nutrition: url: https://medicalxpress.com/rss-feed/search/?search=nutrition r/FoodNerds: url: https://www.reddit.com/r/FoodNerds/new/.rss shorten: false sub: url: pattern: ^https://www\.reddit\.com/r/.+?/comments/(?P<id>.+?)/.+$ repl: https://redd.it/\g<id> "##some_chan2": ArXiv:cs.AI: &ArXiv url: http://export.arxiv.org/rss/cs.AI period: 1.5 https: true shorten: false group: ArXiv:cs alerts: empty: false format: re: title: '^(?P<name>.+?)\.?\ \(arXiv:.+(?P<ver>v\d+)\ ' str: title: '{name}' url: '{url}{ver}' ArXiv:cs.NE: <<: *ArXiv url: http://export.arxiv.org/rss/cs.NE ArXiv:stat.ML: <<: *ArXiv url: http://export.arxiv.org/rss/stat.ML group: null AWS:status: url: https://status.aws.amazon.com/rss/all.rss period: .2 https: true new: none sub: title: pattern: ^(?:Informational\ message|Service\ is\ operating\ normally):\ \[RESOLVED\] repl: '[RESOLVED]' format: re: id: /\#(?P<service>[^_]+) str: title: '[{service}] {title} | {summary}' url: '{id}' Fb:Research: url: https://research.fb.com/publications/ hext: |- <div> <a href:link><h3 @text:title/></a> <div class="areas-wrapper"><a href @text:category/></div> </div> <div><form class="download-form" action/></div> whitelist: category: - ^(?:Facebook\ AI\ Research|Machine\ Learning|Natural\ Language\ Processing\ \&\ Speech)$ InfoWorld: url: https://www.infoworld.com/index.rss order: reverse j:MDPI:N: # https://www.mdpi.com/journal/nutrients (open access) url: https://www.mdpi.com/rss/journal/nutrients www: false KDnuggets: url: https://us-east1-ml-feeds.cloudfunctions.net/kdnuggets new: some libraries.io/pypi/scikit-learn: url: https://libraries.io/pypi/scikit-learn/versions.atom new: none period: 8 shorten: false MedRxiv: url: - https://connect.medrxiv.org/medrxiv_xml.php?subject=Health_Informatics - https://connect.medrxiv.org/medrxiv_xml.php?subject=Nutrition alerts: read: false https: true r/MachineLearning:100+: url: https://www.reddit.com/r/MachineLearning/hot/.json?limit=50 jmespath: 'data.children[*].data | [?score >= `100`].{title: title, link: join(``, [`https://redd.it/`, id])}' shorten: false r/wallstreetbets:50+: url: https://www.reddit.com/r/wallstreetbets/hot/.json?limit=98 jmespath: 'data.children[*].data | [?(not_null(link_flair_text) && score >= `50`)].{title: join(``, [`[`, link_flair_text, `] `, title]), link: join(``, [`https://redd.it/`, id]), category: link_flair_text}' emoji: false shorten: false blacklist: category: - ^(?:Daily\ Discussion|Gain|Loss|Meme|Weekend\ Discussion|YOLO)$ PwC:Latest: url: https://us-east1-ml-feeds.cloudfunctions.net/pwc/latest period: 0.5 dedup: channel PwC:Trending: url: https://us-east1-ml-feeds.cloudfunctions.net/pwc/trending period: 0.5 dedup: channel SeekingAlpha: period: 0.2 sub: url: pattern: ^(?P<main_url>https://seekingalpha\.com/[a-z]+/[0-9]+).*$ repl: \g<main_url> shorten: false topic: "Daily calendar": \b(?i:economic\ calendar)\b "Daily prep": '^Wall\ Street\ Breakfast:\ ' "Hourly status": ^On\ the\ hour$ url: - https://seekingalpha.com/market_currents.xml - https://seekingalpha.com/feed.xml - https://seekingalpha.com/tag/etf-portfolio-strategy.xml - https://seekingalpha.com/tag/wall-st-breakfast.xml SSRN: url: https://papers.ssrn.com/sol3/Jeljour_results.cfm?form_name=journalBrowse&journal_id=3526423&Network=no&lim=false&npage=1 hext: select: <a href:link href^="https://ssrn.com/abstract=" @text:title /> follow: <a class="jeljour_pagination_number" @text:prepend("https://papers.ssrn.com/sol3/Jeljour_results.cfm?form_name=journalBrowse&journal_id=3526423&Network=no&lim=false&npage="):url/> period: 6 TalkRL: url: https://www.talkrl.com/feed period: 8 message: title: false summary: true YT:3Blue1Brown: &YT url: https://www.youtube.com/feeds/videos.xml?channel_id=UCYO_jab_esuFRV4b17AJtAw period: 12 shorten: false style: name: bg: red fg: white bold: true sub: url: pattern: ^https://www\.youtube\.com/watch\?v=(?P<id>.+?)$ repl: https://youtu.be/\g<id> YT:AGI: url: https://www.youtube.com/results?search_query=%22artificial+general+intelligence%22&sp=CAISBBABGAI%253D hext: <a href:filter("/watch\?v=(.+)"):prepend("https://youtu.be/"):link href^="/watch?v=" title:title/> period: 12 shorten: false alerts: emptied: true blacklist: title: - \bWikipedia\ audio\ article\b YT:LexFridman: <<: *YT url: https://www.youtube.com/feeds/videos.xml?channel_id=UCSHZKyawb77ixDdsGog4iWA whitelist: title: - \bAGI\b Global settings
Mandatory
host: IRC server address. ssl_port: IRC server SSL port. ssl_verify: If false, the TLS/SSL certificate is not verified. Its default is true. nick: This is a registered IRC nick. If the nick is in use, it will be regained. Ensure that the email verification of the registered nick, as applicable to many IRC servers, is complete. Without this email verification being completed, the bot can fail to receive the required event 900 and therefore fail to function. Recommended
admin: Administrative commands by this user pattern are accepted and executed. Its format is nick!ident@host. An example is JDoe11!sid654321@gateway/web/irccloud.com/x-*. A case-insensitive pattern match is tested for using fnmatch. alerts_channel: Some but not all warning and error alerts are sent to this channel. Its default value is ##{nick}-alerts. The key {nick}, if present in the value, is formatted with the actual nick. For example, if the nick is MyFeedBot, alerts will by default be sent to ##MyFeedBot-alerts. Since a channel name starts with #, the name if provided must be quoted. It is recommended that the alerts channel be registered and monitored. mode: This can for example be +igR for Libera and +igpR for Rizon. Optional
mirror: If specified as a channel name, all posts across all channels are mirrored to this channel. This however doubles the time between consecutive posts in any given channel. Mirroring can however individually be disabled for a feed by setting <feed>.mirror. publish.github: This is the username and repo name of a GitHub repo, e.g. feedarchive/libera-feedbot-live. All posts are published to the repo, thereby providing a basic option to archive them. A new CSV file is written to the repo for each posted feed having one or more new posts. The following requirements apply: The repo must exist; it is not created by the bot. It is recommended that an empty new repo is used. If the repo is of public interest, it can be requested to be moved into the feedarchive organization by filing an issue. The GitHub user must have access to write to the repo. It is recommended that a dedicated new service account be used, not your primary user account. A GitHub personal access token is required with access to the entire repo scope. The repo scope is used for making commits. The token is provisioned for the bot via the GITHUB_TOKEN secret environment variable. Developer
log.irc: If true, low level IRC events are logged by miniirc. These are quite noisy. Its default is false. once: If true, each feed is queued only once. It is for testing purposes. Its default is false. tracemalloc: If true, memory allocation tracing is enabled. The top usage and positive-diff statistics are then logged hourly. It is for diagnostic purposes. Its default is false. Feed-specific settings
A feed is defined under a channel as in the sample configuration. The feed's key represents its name.
The order of execution of the interacting operations is: redirect, blacklist, whitelist, https, www, emoji, sub, format, shorten. Refer to the sample configuration for usage examples.
YAML anchors and references can be used to reuse nodes. Examples of this are in the sample.
Mandatory
<feed>.url: This is either a single URL or a list of URLs of the feed. If a list, the URLs are read in sequence with an interval of one second between them. Optional
These are optional and are independent of each other:
<feed>.alerts.empty: If true, an alert is sent if any source URL of the feed has no entries before their validation. If false, such an alert is not sent. Its default value is true. <feed>.alerts.emptied: If true, an alert is sent if the feed has entries before but not after their validation. If false, such an alert is not sent. Its default value is false. <feed>.alerts.read: If true, an alert is sent if an error occurs three or more consecutive times when reading or processing the feed, but no more than once every 15 minutes. If false, such an alert is not sent. Its default value is true. <feed>.blacklist.category: This is an arbitrarily nested dictionary or list or their mix of regular expression patterns that result in an entry being skipped if a search finds any of the patterns in any of the categories of the entry. The nesting permits lists to be creatively reused between feeds via YAML anchors and references. <feed>.blacklist.title: This is an arbitrarily nested dictionary or list or their mix of regular expression patterns that result in an entry being skipped if a search finds any of the patterns in the title. The nesting permits lists to be creatively reused between feeds via YAML anchors and references. <feed>.blacklist.url: Similar to <feed>.blacklist.title. <feed>.dedup: This indicates how to deduplicate posts for the feed, thereby preventing them from being reposted. The default value is feed (per-feed per-channel), and an alternate possible value is channel (per-channel). <feed>.emoji: If false, emojis in entry titles are removed. Its default value is null. <feed>.group: If a string, this delays the processing of a feed that has just been read until all other feeds having the same group are also read. This encourages multiple feeds having the same group to be be posted in succession, except if interrupted by conversation. It is however possible that unrelated feeds of any channel gets posted between ones having the same group. To explicitly specify the absence of a group when using a YAML reference, the value can be specified as null. It is recommended that feeds in the same group have the same period. <feed>.https: If true, entry links that start with http:// are changed to start with https:// instead. Its default value is false. <feed>.message.summary: If true, the entry summary (description) is included in its message. The entry title, if included, is then formatted bold. This is applied using IRC formatting if a style is defined for the feed, otherwise using unicode formatting. The default value is false. <feed>.message.title: If false, the entry title is not included in its message. Its default value is true. <feed>.mirror: If false, mirroring is disabled for this feed. Its default value is true, subject to the global-setting for mirroring. <feed>.new: This indicates up to how many entries of a new feed to post. A new feed is defined as one with no prior posts in its channel. The default value is some which is interpreted as 3. The default is intended to limit flooding a channel when one or more new feeds are added. A string value of none is interpreted as 0 and will skip all entries for a new feed. A value of all will skip no entries for a new feed; it is not recommended and should be used sparingly if at all. In any case, future entries in the feed are not affected by this option on subsequent reads, and they are all forwarded without a limit. <feed>.order: If reverse, the order of the entries is reversed. <feed>.period: This indicates how frequently to read the feed in hours on an average. Its default value is 1. Conservative polling is recommended. Any value below 0.2 is changed to a minimum of 0.2. Note that 0.2 hours is equal to 12 minutes. To make service restarts safer by preventing excessive reads, the first read is delayed by half the period. To better distribute the load of reading multiple feeds, a uniformly distributed random ±5% is applied to the period for each read. <feed>.redirect: This indicates whether to substitute each entry URL with its redirect target. The default value is false. <feed>.shorten: This indicates whether to post shortened URLs for the feed. The default value is true. The alternative value false is recommended if the URL is naturally small, or if sub or format can be used to make it small. If a "Blacklisted long URL" error is experienced for a reasonable website which should not be blacklisted, it can be reported here, using this issue as an example. <feed>.style.name.bg: This is a string representing the name of a background color applied to the feed's name. It can be one of: white, black, blue, green, red, brown, purple, orange, yellow, lime, teal, aqua, royal, pink, grey, silver. The channel modes must allow formatting for this option to be effective. <feed>.style.name.bold: If true, bold formatting is applied to the feed's name. Its default value is false. The channel modes must allow formatting for this option to be effective. <feed>.style.name.fg: Foreground color similar to <feed>.style.name.bg. <feed>.topic: This updates the channel topic with the short URL of a matching entry. It requires auto-op (+O) to allow the topic to be updated. The topic is divided into logical sections separated by | (<space><pipe><space>). For any matching entry, only its matching section in the topic is updated. Its value can be a dictionary in which each key is a section name and each value is a regular expression pattern. If a regular expression search matches an entry's title, the section in the topic is updated with the entry's short URL. The topic's length is not checked. <feed>.whitelist.category: This is an arbitrarily nested dictionary or list or their mix of regular expression patterns that result in an entry being skipped unless a search finds any of the patterns in any of the categories of the entry. The nesting permits lists to be creatively reused between feeds via YAML anchors and references. <feed>.whitelist.explain: This applies only to <feed>.whitelist.title. It can be useful for understanding which portion of a post's title matched the whitelist. If true, the first match of each posted title is italicized. This is applied using IRC formatting if a style is defined for the feed, otherwise using unicode formatting. For example, "This is a matching sample title". The default value is false. <feed>.whitelist.title: This is an arbitrarily nested dictionary or list from which all leaf values are used. The leaf values are regular expression patterns. This result in an entry being skipped unless a search finds any of the patterns in the title. The nesting permits lists to be creatively reused between feeds via YAML anchors and references. <feed>.whitelist.url: Similar to <feed>.whitelist.title. <feed>.www: If false, entry links that contain the www. prefix are changed to remove this prefix. Its default value is null. Parser
For a non-XML feed, one of the following non-default parsers can be used. Multiple parsers cannot be used for a feed. The parsers are searched for in the alphabetical order listed below, and the first to be found is used. Each parsed entry must at a minimum return a title, a link, an optional summary (description), and zero or more values for category The title can be a string or a list of strings.
<feed>.hext: This is a string representing the hext DSL for parsing a list of entry dictionaries from an HTML web page. Before using, it can be tested in the form here. Note that max_searches is set to 100_000 to protect against resource exhaustion. <feed>.jmespath: This is a string representing the jmespath DSL for parsing a list of entry dictionaries from JSON. Before using, it can be tested in the form here. <feed>.pandas: This is a string command evaluated using pandas for parsing a dataframe of entries. The raw content is made available to the parser as a file-like object named file. This parser uses eval which is unsafe, and so its use must be confirmed to be safe. The provisioned packages are json, numpy (as np), and pandas (as pd). The value requires compatibility with the versions of pandas and numpy defined in requirements.txt, noting that these version requirements are expected to be routinely updated. For recursive crawling, the value of a parser can alternatively be:
<feed>.<parser>.select: This is the string which was hitherto documented as the value for <feed>.<parser>.. The parser uses it to return the entries to post. <feed>.<parser>.follow: The is an optional string which the parser uses to return zero or more additional URLs to read. The returned URLs can a list of strings or a list of dictionaries with the key url. Crawling applies recursively to each returned URL. Each unique URL is read once. There is an interval of at least one second between the end of a read and the start of the next read. Care should nevertheless be taken to avoid crawling a large number of URLs. Some sites require a custom user agent or other custom headers for successful scraping; such a customization can be requested by creating an issue.
Conditional
The sample configuration above contains examples of these:
<feed>.format.re.title: This is a single regular expression pattern that is searched for in the title. It is used to collect named key-value pairs from the match if there is one. <feed>.format.re.url: Similar to <feed>.format.re.title. <feed>.format.str.title: The key-value pairs collected using <feed>.format.re.title and <feed>.format.re.url, both of which are optional, are combined along with the default additions of title, url, categories, and feed.url as keys. Any additional keys returned by the parser are also available. The key-value pairs are used to format the provided quoted title string. If the title formatting fails for any reason, a warning is logged, and the title remains unchanged. The default value is {title}. <feed>.format.str.url: Similar to <feed>.format.str.title. The default value is {url}. If this is specified, it can sometimes be relevant to set shorten to false for the feed. <feed>.sub.summary.pattern: This is a single regular expression pattern that if found results in the entry summary being substituted. <feed>.sub.summary.repl: If <feed>.sub.summary.pattern is found, the entry summary is replaced with this replacement, otherwise it is forwarded unchanged. <feed>.sub.title.pattern: Similar to <feed>.sub.summary.pattern. <feed>.sub.title.repl: Similar to <feed>.sub.summary.repl. <feed>.sub.url.pattern: Similar to <feed>.sub.summary.pattern. If a pattern is specified, it can sometimes be relevant to set shorten to false for the feed. <feed>.sub.url.repl: Similar to <feed>.sub.summary.repl. Feed default settings
A global default value can optionally be set under defaults for some feed-specific settings, namely new and shorten. This value overrides its internal default. It facilitates not having to set the same value individually for many feeds.
Refer to "Feed-specific settings" for the possible values and internal defaults of these settings. Refer to the embedded sample configuration for a usage example.
Commands
Commands can be sent to the bot either as a private message or as a directed public message. Private messages may however be prohibited for security purposes using the mode configuration. Public messages to the bot must be directed as MyBotNick: my_command.
Administrative
Administrative commands are accepted from the configured admin. If admin is not configured, the commands are not processed. It is expected but not required that administrative commands to the bot will typically be sent in the alerts_channel. The supported commands are:
exit: Gracefully exit with code 0. The exit is delayed until any feeds that are currently being posted finish posting and being written to the database. If running the bot as a Docker Compose service, using this command with restart: on-failure will (due to code 0) prevent the bot from automatically restarting. Note that a repeated invocation of this command has no effect. fail: Similar to exit but with code 1. If running the bot as a Docker Compose service, using this command with restart: on-failure will (due to a nonzero code) cause the bot to automatically be restarted. quit: Alias of exit. Deployment
As a reminder, it is recommended that the alerts channel be registered and monitored.
It is recommended that the bot be auto-voiced (+V) in each channel. Failing this, messages from the bot risk being silently dropped by the server. This is despite the bot-enforced limit of two seconds per message across the server.
It is recommended that the bot be run as a Docker container using using Docker ≥18.09.2, possibly with Docker Compose ≥1.24.0. To run the bot using Docker Compose, create or add to a version-controlled docker-compose.yml file such as:
version: '3.7' services: irc-rss-feed-bot: container_name: irc-rss-feed-bot image: ascensive/irc-rss-feed-bot:<VERSION> # network_mode: host # If having DNS name resolution issues. restart: on-failure # restart: always logging: options: max-size: 2m max-file: "5" volumes: - ./irc-rss-feed-bot:/config env_file: - ./irc-rss-feed-bot/secrets.env environment: TZ: America/New_York # Select TZ database name from https://en.wikipedia.org/wiki/List_of_tz_database_time_zones In the above service definition in docker-compose.yml:
image: Use a specific versioned tag, e.g. 0.12.0. volumes: Customize the relative path to the previously created config.yaml file, e.g. ./irc-rss-feed-bot. This volume source directory must be writable by the container using the UID defined in the Dockerfile; it is 999. A simple way to ensure it is writable is to run a command such as chmod -R a+w ./irc-rss-feed-bot once on the host. env_file: Customize the relative path to secrets.env. environment: Optionally customize the environment variable TZ to the preferred time zone as represented by a TZ database name. Note that the date and time are prefixed in each log message. From the directory containing docker-compose.yml, run docker-compose up -d irc-rss-feed-bot. Use docker logs -f irc-rss-feed-bot to see and follow informational logs.
Maintenance
Service
It is recommended that the supported administrative commands be used together with Docker Compose or a comparable container service manager to shutdown or restart the service.
Config
If config.yaml is updated, the container must be restarted to use the updated file. If secrets.env or the service definition in docker-compose.yml are updated, the container must be recreated (and not merely restarted) to use the updated file. Database
A posts.v2.db database file is written by the bot in the same directory as config.yaml. This database file must be preserved with routine backups. After restoring a backup, before starting the container, ensure the database file is writable by running a command such as chmod a+w ./irc-rss-feed-bot/posts.v2.db. The database file grows as new posts are made. For the most part this indefinite growth can be ignored. Currently, the standard approach for handling this, if necessary, is to stop the bot and delete the database file if it has grown unacceptably large. Restarting the bot after deleting the database will then create a new database file, and all configured feeds will be handled as new. This deletion is however discouraged as a routine measure. Disk cache
An ephemeral directory /app/.ircrssfeedbot_cache is written by the bot in the container. It contains one or more independent disk caches. The size of each independent disk cache in this directory is limited to approximately 2 GiB. If needed, this directory can optionally be mounted as an external volume.0 downloads
(0 reviews)0 comments
Submitted
-

LioBot (Liona)
Laravel.io's irc bot for #laravel on freenode.
This version is designed to be deployed on Heroku. This README was generated for you by hubot to help get you started. Definitely update and improve to talk about your own instance, how to use and deploy, what functionality he has, etc!
Testing Hubot Locally
You can test your hubot by running the following.
% bin/hubot You'll see some start up output about where your scripts come from and a prompt.
[Sun, 04 Dec 2011 18:41:11 GMT] INFO Loading adapter shell [Sun, 04 Dec 2011 18:41:11 GMT] INFO Loading scripts from /home/tomb/Development/hubot/scripts [Sun, 04 Dec 2011 18:41:11 GMT] INFO Loading scripts from /home/tomb/Development/hubot/src/scripts Hubot> Then you can interact with hubot by typing hubot help.
Hubot> hubot help Hubot> animate me <query> - The same thing as `image me`, except adds a few convert me <expression> to <units> - Convert expression to given units. help - Displays all of the help commands that Hubot knows about. ... Scripting
Take a look at the scripts in the ./scripts folder for examples. Delete any scripts you think are useless or boring. Add whatever functionality you want hubot to have. Read up on what you can do with hubot in the Scripting Guide.
Redis Persistence
If you are going to use the redis-brain.coffee script from hubot-scripts (strongly suggested), you will need to add the Redis to Go addon on Heroku which requires a verified account or you can create an account at Redis to Go and manually set the REDISTOGO_URL variable.
% heroku config:add REDISTOGO_URL="..." If you don't require any persistence feel free to remove the redis-brain.coffee from hubot-scripts.json and you don't need to worry about redis at all.
Adapters
Adapters are the interface to the service you want your hubot to run on. This can be something like Campfire or IRC. There are a number of third party adapters that the community have contributed. Check Hubot Adapters for the available ones.
If you would like to run a non-Campfire or shell adapter you will need to add the adapter package as a dependency to the package.json file in the dependencies section.
Once you've added the dependency and run npm install to install it you can then run hubot with the adapter.
% bin/hubot -a <adapter> Where <adapter> is the name of your adapter without the hubot- prefix.
hubot-scripts
There will inevitably be functionality that everyone will want. Instead of adding it to hubot itself, you can submit pull requests to hubot-scripts.
To enable scripts from the hubot-scripts package, add the script name with extension as a double quoted string to the hubot-scripts.json file in this repo.
external-scripts
Tired of waiting for your script to be merged into hubot-scripts? Want to maintain the repository and package yourself? Then this added functionality maybe for you!
Hubot is now able to load scripts from third-party npm packages! To enable this functionality you can follow the following steps.
Add the packages as dependencies into your package.json npm install to make sure those packages are installed To enable third-party scripts that you've added you will need to add the package name as a double quoted string to the external-scripts.json file in this repo.
Deployment
% heroku create --stack cedar % git push heroku master % heroku ps:scale app=1 If your Heroku account has been verified you can run the following to enable and add the Redis to Go addon to your app.
% heroku addons:add redistogo:nano If you run into any problems, checkout Heroku's docs.
You'll need to edit the Procfile to set the name of your hubot.
More detailed documentation can be found on the deploying hubot onto Heroku wiki page.
Deploying to UNIX or Windows
If you would like to deploy to either a UNIX operating system or Windows. Please check out the deploying hubot onto UNIX and deploying hubot onto Windows wiki pages.
Campfire Variables
If you are using the Campfire adapter you will need to set some environment variables. Refer to the documentation for other adapters and the configuraiton of those, links to the adapters can be found on Hubot Adapters.
Create a separate Campfire user for your bot and get their token from the web UI.
% heroku config:add HUBOT_CAMPFIRE_TOKEN="..." Get the numeric IDs of the rooms you want the bot to join, comma delimited. If you want the bot to connect to https://mysubdomain.campfirenow.com/room/42 and https://mysubdomain.campfirenow.com/room/1024 then you'd add it like this:
% heroku config:add HUBOT_CAMPFIRE_ROOMS="42,1024" Add the subdomain hubot should connect to. If you web URL looks like http://mysubdomain.campfirenow.com then you'd add it like this:
% heroku config:add HUBOT_CAMPFIRE_ACCOUNT="mysubdomain" Restart the bot
You may want to get comfortable with heroku logs and heroku restart if you're having issues.
0 downloads
(0 reviews)0 comments
Submitted
-

yossarian-bot
An entertaining IRC bot that's easy to extend.
Features:
Simple real-time administration. Unix fortunes (fortune must be present) Catch-22 quotes UrbanDictionary queries Wolfram|Alpha queries Smart weather queries (Wunderground) Google searches YouTube searches ROT13 message "encryption" Magic 8 Ball queries Dictionary queries (Merriam-Webster) Cleverbot discussions Channel 'seen' log Link compression (TinyURL) ...and much more! Installation
First, clone the repo and install yossarian-bot's dependencies:
$ git clone https://github.com/woodruffw/yossarian-bot $ cd yossarian-bot $ bundle install If you get errors during the bundle installation process, make sure that you're using Ruby 2.7 and have Ruby's development headers installed. You may need them from your package manager. Earlier versions of Ruby might work, but are not guaranteed or tested.
yossarian-bot also requires API keys for several services. Make sure that they are exported to the environment (or set in the configuration) as follows:
Wolfram|Alpha - WOLFRAM_ALPHA_APPID_KEY Weather Underground - WUNDERGROUND_API_KEY WeatherStack - WEATHERSTACK_API_KEY Merriam-Webster - MERRIAM_WEBSTER_API_KEY YouTube (v3) - YOUTUBE_API_KEY Last.fm - LASTFM_API_KEY, LASTFM_API_SECRET Open Exchange Rates - OEX_API_KEY Giphy - GIPHY_API_KEY BreweryDB - BREWERYDB_API_KEY AirQuality - AIRNOW_API_KEY OMDB - OMDB_API_KEY Additionally, the fortune utility must be present in order for Unix fortunes to work correctly. Some package managers also provide the fortunes, fortunes-off, and fortunes-bofh-excuses packages for additional fortune messages.
Running
Once all dependencies are installed, yossarian-bot can be run as follows:
$ ruby bot-control.rb start $ # OR: $ ruby yossarian-bot.rb # not run in background Using Docker
docker build -t yossarian-bot:latest . docker run -v $PWD/config.yml:/config.yml yossarian-bot Using the bot
Configuration Options
yossarian-bot is configured via a YAML file named config.yml.
Look at the example config.yml to see a list of optional and required keys.
Commands
There are a bunch of commands that yossarian-bot accepts. You can see a complete list in the COMMANDS file.
Matches
yossarian-bot matches all HTTP links and messages the title of the linked HTML page. This feature can be disabled by adding LinkTitling to the server's disabled_plugins array in config.yml.
Messages of the form s/(.+)/(.+) are also matched, and the first pattern matched is applied to the user's last previous message, with the second match replacing it. For example, a typo like "this is a setnence" can be corrected with s/setnence/sentence. This feature can be disabled by adding RegexReplace to the server's disabled_plugins array in config.yml.
0 downloads
(0 reviews)0 comments
Submitted
-
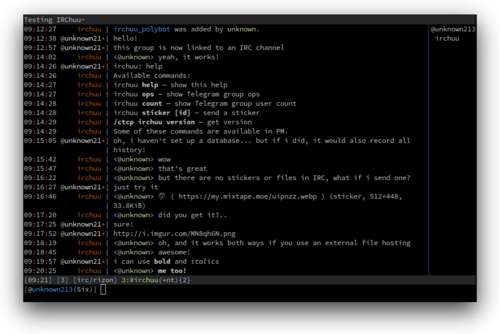
irchuu
Features
Relays messages between a Telegram (super)group and an IRC channel Lightweight, written in Go. Consumes only around 10MiB RAM! IRC authentication using SASL or NickServ (optional) Keeps log of the chat in a PostgreSQL database (those who recently joined the IRC channel can view history!) Preserves markup: bold in Telegram will remain bold in IRC All Telegram media types support; serves or uploads files so they are accessible in IRC All Telegram features like forwards, replies and edits are also supported Coloured nicknames in IRC (optional) Telegram group administrators can moderate the IRC channel and vice versa ...and this is not a complete list! Setup
Installation
You need to install golang, git and configure your $GOPATH. Just set $GOPATH environment variable to a writable directory and add $GOPATH/bin to your system $PATH.
After that, install IRChuu~:
$ go get github.com/26000/irchuu/... Upgrade with:
$ go get -u github.com/26000/irchuu/... Configuration
Run IRChuu~ for the first time and it will create a configuration file (you can also use -data and -config command-line arguments to specify a custom path):
$ irchuu IRChuu! v0.6.0 (https://github.com/26000/irchuu) 2017/04/01 15:26:03 New configuration file was populated. Edit /home/26000/.config/irchuu.conf and run `irchuu` again! Now edit the configuration file with your favourite editor (mine is vim, but I thought nano is more popular. Alternatively, you can just use a GUI editor like Kate):
$ nano ~/.config/irchuu.conf The variables you must set are:
token, group in the [telegram] section server, port, ssl, nick and channel in the [irc] section probably serverpassword, password, sasl and chanpassword for IRC authentication If you don't know where to get the Telegram token and groupname, refer to the next section.
Others are completely optional. The configuration file is well-documented, but if you have problems, feel free to open an issue on GitHub.
Telegram bot setup
For IRChuu to work, you will need to create a Telegram bot as it works through the Telegram bot API. This is pretty simple:
Message @botfather inside Telegram. Send /newbot command. It will ask some questions, answer all of them. You will have to think of a name and a nickname for your bot. @botfather will send you a token. Insert it into your configuration file. Type /setprivacy and choose your newly created bot nickname on the inline keyboard. Then choose Disable. This is important! If you forget to do it, messages from Telegram won't be relayed to IRC. Optionally, type /setuserpic and upload a cute picure for your relay Add your bot to your Telegram group (Add members and type the bot username there) Launch IRChuu~ (just type irchuu in console once more) Your bot will leave a message with the group id. That's totally ok, just copy the id into your config file, stop IRChuu (hit Ctrl+C in the terminal where IRChuu~ is running) All set, now just launch IRChuu for the third time and enjoy! IRC setup
This one is easier. You can just insert your server and channel addresses into your configuration file and choose a nickname. If that nickname is already taken, IRChuu will think of a new one. If you want to own that nickname so that nobody takes it, register it and enter the password in the configuration file. Refer to your server's NickServ focumentation for details.
Usage
Just type irchuu.
Contributing
Feel free to fork this repo and make PRs. If you encounter a bug, please open an issue — that also helps! I will also be happy if you give IRChuu a star on GitHub.
0 downloads
(0 reviews)0 comments
Submitted
-

Japanese-Tools
These are some scripts that help me learn Japanese.
Most scripts are supposed to be used as plugins for an IRC bot or run on a shell. I find the following aliases quite useful:
alias ja="$JAPANESE_TOOLS/jmdict/jm.sh" alias wa="$JAPANESE_TOOLS/jmdict/wa.sh" alias rtk="$JAPANESE_TOOLS/rtk/rtk.sh" alias gd="$JAPANESE_TOOLS/google_dictionary/gd.sh" I do most of my dictionary lookups with these aliases.
All scripts have only been tested on Ubuntu 12.04 and later. There are a few dependencies not present on a default Ubuntu system. You can install them with
$ sudo apt install mecab-jumandic-utf8 mecab kakasi xmlstarlet xsltproc python-irclib sqlite3 bc liburi-perl tesseract-ocr imagemagick audio/
find_audio.sh finds an audio version of a given Japanese word on languagepod101.
$ ./find_audio.sh 夜空 Audio for 夜空 [よぞら]: http://tinyurl.com/p8aq8jo compare_encoding
Compares the size of different encodings of the same Japanese Wikipedia article. In almost all cases UTF-8 is smaller than UTF-16.
$ ./compare_encoding.sh 夜空 UTF-8 vs. UTF-16: 91213 vs. 156876 bytes. UTF-8 wins by 41.8%. gettext/
Internationalization support. Currently supported languages:
English German Polish Be sure to run gettext/regenerate_mo_files.sh if you would like to use a translation.
google_count
Counts the number of Google results. Uses google.co.jp for queries containing Japanese characters and google.com otherwise.
google_dictionary/
gd.sh looks up English words in the Google dictionary.
$ ./gd.sh diligent /ˈdiləjənt/ having or showing care and conscientiousness in one's work or duties Currently broken because it appears like Google shut down their dictionary JSON API.
google_translate/
gt.sh translates words and sentences using Google Translate. The target language is determined by the environment variable LANG, but it can also be specified explicitly.
./gt.sh My hovercraft is full of eels. 私のホバークラフトは鰻がいっぱいです。 ./gt.sh it My hovercraft is full of eels. it: Il mio hovercraft è pieno di anguille. ./gt.sh Il mio hovercraft è pieno di anguille. My hovercraft is full of eels. Currently broken because Google shut down the translate API.
jmdict/
jm.sh provides jmdict lookups and wa.sh wadoku lookups. Works best for Japanese->English (or Japanese->German), not so well for the reverse direction. This is because jmdict is a Japanese English dictionary and not an English Japanese dictionary.
To start, you first need to run the scripts prepare_jmdict.sh and prepare_wadoku.sh. This will download and process the respective dictionary files.
$ ./jm.sh 村長 村長 [そんちょう] (n), village headman 市長村長選挙 [しちょうそんちょうせんきょ] (n), mayoral election kana/
A simple hiragana and katakana trainer.
Example IRC session
<Christoph> !hira help <nihongobot> Start with "!hira <level> [count]". Known levels are 0 to 10. To learn more about some level please use "!hira help <level>". <nihongobot> To only see the differences between consecutive levels, please use "!hira helpdiff <level>". <Christoph> !hira 5 <nihongobot> Please write in romaji: す と に ね へ <Christoph> !hira su to ni ne he <nihongobot> Perfect! 5 of 5. Statistics for Christoph: 44.64% of 280 characters correct. <nihongobot> Please write in romaji: は と ぬ ほ な kanjidic/
Implements a lookup in kanjidic: http://www.csse.monash.edu.au/~jwb/kanjidic.html
$ ./kanjidic.sh 日本語 日: 4 strokes. ニチ, ジツ, ひ, -び, -か. In names: あ, あき, いる, く, くさ, こう, す, たち, に, にっ, につ, へ {day, sun, Japan, counter for days} 本: 5 strokes. ホン, もと. In names: まと {book, present, main, origin, true, real, counter for long cylindrical things} 語: 14 strokes. ゴ, かた.る, かた.らう {word, speech, language} kumitate_quiz/
A quiz asking JLPT style 文の組み立て questions. Only works as an IRC plugin for now.
Example IRC session
<Flamerokz> !kuiz skm2 <nihongobot> Please choose [1-4]: 周囲の人たちの _ _ ★ _ と思う。 (1: 協力を 2: 優勝は 3: 無理だった 4: 抜きにしては). <Flamerokz> !kuiz 2 <nihongobot> Flamerokz: Correct! (2: 優勝は) Example question file
A question file (a file ending in .txt in kumitate_quiz/questions/) should contains lines of the following form:
周囲の人たちの _ _ ★ _ と思う。|協力を,優勝は,無理だった,抜きにしては|2 lhc
This script has nothing to do with Japanese. It OCRs the image on http://op-webtools.web.cern.ch/op-webtools/vistar/vistars.php?usr=LHC1 to provide live statistics of the status of the LHC.
reading/
read.py converts kanji to kana using mecab.
$ ./read.py 鬱蒼たる樹海の中に舞う人の如き影が在った。 鬱蒼[うっそう]たる 樹海[じゅかい] の 中[なか] に 舞[ま]う 人[じん] の 如[ごと]き 影[かげ] が 在[あ]った 。 reading_quiz/
A quiz asking kanji -> kana questions. Only works as an IRC plugin for now.
Example IRC session
<Christoph> !quiz jlpt2 <nihongobot> Please read: 発見 <Christoph> !quiz はっけん <nihongobot> Christoph: Correct! (はっけん: (n,vs) 1. discovery, 2. detection, 3. finding) romaji/
romaji.sh converts kanji and kana to romaji using mecab.
$ ./romaji.sh 鬱蒼たる樹海の中に舞う人の如き影が在った。 ussoutaru jukai no naka ni mau jin no gotoki kage ga atta 。 rtk/
rtk.sh looks up keywords, kanji and numbers. The keywords and numbers refer to Heisig’s amazing book “Remembering the Kanji”.
$ ./rtk.sh 城壁 #362: castle 城 | #1500: wall 壁 $ ./rtk.sh star #1556: star 星, #237: stare 眺, #1476: starve 餓, #2532: star-anise 樒, #2872: start 孟, #2376: mustard 芥 $ ./rtk.sh 1 2 3 #1: one 一 | #2: two 二 | #3: three 三 simple_bot/
As the name says, this is a simple IRC bot. You can start it with:
$ ./bot.py <server[:port]> <channel> <nickname> [NickServ password] It uses all the other scripts.
0 downloads
(0 reviews)0 comments
Submitted
-

🍯 honeybot py
HoneyBot is a python-based IRC bot. (python3.7) | If you want to just run the bot, go to the quick start section
Feel free to contribute to the project!
🕹 Project Motivation
Implementing the project in Java was weird, py's connect was sleek. Thus, the project stack was shifted over to Python. If you can think of any features, plugins, or functionality you wish to see in the project. Feel free to add it yourself, or create an issue detailing your ideas. We highly recommend you attempt to implement it yourself first and ask for help in our discord server !
Psst. Since I learnt py through this bot, we decided to keep a new-comers friendly policy. Feeling lost? Just ping.
✂ Current Features
🍬 OOP architecture 🛰️ keyword parameters 🌵 password security with config file [disabled for now] 🔌 now with plugins ⛰️ GUI clients
GUI clients are used to manage plugins, launch bot as well as specify credentials.
CPP client by @Macr0Nerd0 downloads
(0 reviews)0 comments
Submitted
-

CloudBot
THIS PROJECT HAS MOVED TO TotallyNotRobots/CloudBot
CloudBot is a simple, fast, expandable open-source Python IRC Bot!
Getting CloudBot
There are currently four different branches of this repository, each with a different level of stability:
gonzobot (stable): This branch contains everything in the master branch plus additional plugins added for Snoonet IRC. This branch is the currently maintained branch which will also contain many fixes for various bugs from the master branch. gonzobot-dev (unstable): This branch is based off of the gonzobot branch and includes new plugins that are not fully tested. master (stable (old)): This branch contains stable, tested code. This branch is based directly on the upstream master branch and is not currently maintained. python3.4 (unstable (old)): This is the outdated testing branch from the upstream repo. New releases will be pushed from python3.4 to master whenever we have a stable version to release. These changes will be merged into gonzobot then deployed. This should happen on a fairly regular basis, so you'll never be too far behind the latest improvements.
Installing CloudBot
Firstly, CloudBot will only run on Python 3.4 or higher. Because we use the asyncio module, you will not be able to use any other versions of Python.
To install CloudBot on *nix (linux, etc), see here
To install CloudBot on Windows, see here
Running CloudBot
Before you run the bot, rename config.default.json to config.json and edit it with your preferred settings. You can check if your JSON is valid using jsonlint.com!
Once you have installed the required dependencies and renamed the config file, you can run the bot! Make sure you are in the correct folder and run the following command:
python3.4 -m cloudbot Note that you can also run the cloudbot/__main__.py file directly, which will work from any directory.
python3.4 CloudBot/cloudbot/__main__.py Specify the path as /path/to/repository/cloudbot/main.py, where cloudbot is inside the repository directory.
Getting help with CloudBot
Documentation
The CloudBot documentation is currently somewhat outdated and may not be correct. If you need any help, please visit our IRC channel and we will be happy to assist you.
To write your own plugins, visit the Plugins Wiki Page.
More at the Wiki Main Page.
Support
The developers reside in #gonzobot-dev on Snoonet and would be glad to help you.
If you think you have found a bug/have a idea/suggestion, please open a issue here on Github and contact us on IRC!
Changelog
See CHANGELOG.md
0 downloads
(0 reviews)0 comments
Submitted
-

Kaguya
Kaguya
A small but powerful IRC bot
Installation
Add kaguya to your list of dependencies in mix.exs: def deps do [{:kaguya, "~> x.y.z"}] end Run mix deps.get
Ensure kaguya is started before your application:
def application do [applications: [:kaguya]] end Configure kaguya in config.exs: config :kaguya, server: "my.irc.server", port: 6666, bot_name: "kaguya", channels: ["#kaguya"] Usage
By default Kaguya won't do much. This is an example of a module which will perform a few simple commands:
defmodule Kaguya.Module.Simple do use Kaguya.Module, "simple" handle "PRIVMSG" do match ["!ping", "!p"], :pingHandler match "hi", :hiHandler match "!say ~message", :sayHandler end defh pingHandler, do: reply "pong!" defh hiHandler(%{user: %{nick: nick}}), do: reply "hi #{nick}!" defh sayHandler(%{"message" => response}), do: reply response end This module defines four commands to be handled:
!ping and !p are aliased to the same handler, which has the bot respond pong!. hi will cause the bot to reply saying "hi" with the persons' nick !say [some message] will have the bot echo the message the user gave. The handler macro can accept up to two different parameters, a map which destructures a message struct, and a map which destructures a match from a command.
You can find a more full featured example in example/basic.ex.
Configuration
server - Hostname or IP address to connect with. String. server_ip_type - IP version to use. Can be either inet or inet6 port - Port to connect on. Integer. bot_name - Name to use by bot. String. channels - List of channels to join. Format: #<name>. List help_cmd - Specifies command to act as help. Defaults to .help. String use_ssl - Specifies whether to use SSL or not. Boolean reconnect_interval - Interval for reconnection in ms. Integer. Not used. server_timeout - Timeout(ms) that determines when server gets disconnected. Integer. When omitted Kaguya does not verifies connectivity with server. It is recommended to set at least few minutes.0 downloads
(0 reviews)0 comments
Submitted
-

irc-bot
An advanced and scriptable PHP IRC bot.
It is designed to run off a local LAMP, WAMP, MAMP stack or just plain PHP installation. No web server is required, only a working PHP installation.
System requirements
In order to run WildPHP, we ask a few things from your system. Notably:
A PHP version equal to or higher than 7.1.0. Command-line access to the system you plan on running WildPHP on. WildPHP will NOT run inside a web server like Apache or Nginx. Do not ask for support for doing so. WildPHP has been tested to work on Linux and macOS. Other platforms are not supported and not guaranteed to work. For the best experience, we recommend either using the included systemd service (adjust it to your needs) or using tmux or screen to allow the bot to run in the background. IRC Community & Support
If you need help or just want to idle in the IRC channel join us at #wildphp@irc.freenode.net. Development discussion in #wildphp-dev@irc.freenode.net.
Features and Functions
Right now this version of the bot is under heavy development, therefore the feature list is not definitive. We will update this once a reliable list becomes available.
Installation
To install the latest development build, you need Composer. Install WildPHP using the following commands:
$ git clone https://github.com/WildPHP/irc-bot $ cd irc-bot $ composer install This will pull all Composer dependencies required to run the bot.
Please note that the bot may be unstable and that it might not even start. Please file a bug if you encounter an issue!
Configuration
Copy the example configuration file and edit it to suit your needs. Carefully read the comments.
$ cp config/config.sample.php config/config.php Running the bot
While you can run the bot in a terminal it is best to run it in tmux or screen so that it can run in background.
$ php bin/wildphp.php Alternatively, a systemd service is included. Edit it (carefully read the comments), then drop it in /etc/systemd/system/. Issue a systemctl daemon-reload afterwards and you should be able to use the service.
Contributors
You can see the full list of contributors in the GitHub repository.
Major & Past Major Contributors
Super3 Pogosheep Matejvelikonja Yoshi2889 TimTims Amunak0 downloads
(0 reviews)0 comments
Submitted
-

teleirc
About
RITlug TeleIRC is a Go implementation of a Telegram <=> IRC bridge. TeleIRC works with any IRC channel and Telegram group. It bridges messages between a Telegram group and an IRC channel.
This bot was originally written for RITlug. Today, it is used by various communities.
Live demo
A public Telegram supergroup and IRC channel (on Freenode) are available for testing. Our developer community is found in these channels.
Telegram IRC (#rit-lug-teleirc @ irc.freenode.net)0 downloads
(0 reviews)0 comments
Submitted
-

bitbot
BitBot
Python3 event-driven modular IRC bot!
Setup
Requirements
$ pip3 install --user -r requirements.txt
Config
See docs/help/config.md.
Backups
If you wish to create backups of your BitBot instance (which you should, borgbackup is a good option), I advise backing up the entirety of ~/.bitbot - where BitBot by-default keeps config files, database files and rotated log files.
Github, Gitea and GitLab web hooks
I run BitBot as-a-service on most popular networks (willing to add more networks!) and offer github/gitea/gitlab webhook to IRC notifications for free to FOSS projects. Contact me for more information!
0 downloads
(0 reviews)0 comments
Submitted
-

KittehIRCClientLib
The Kitteh IRC Client Library (KICL) is a powerful, modern Java IRC library built with NIO using the Netty library to maximize performance and scalability.
0 downloads
(0 reviews)0 comments
Submitted
-

tenyks
Tenyks is a computer program designed to relay messages between connections to IRC networks and custom built services written in any number of languages. More detailed, Tenyks is a service oriented IRC bot rewritten in Go. Service/core communication is handled by ZeroMQ 4 PubSub via json payloads.
The core acts like a relay between IRC channels and remote services. When a message comes in from IRC, that message is turned into a json data structure, then sent over the pipe on a Pub/Sub channel that services can subscribe to. Services then parse or pattern match the message, and possibly respond back via the same method.
This design, while not anything new, is very flexible because one can write their service in any number of languages. The current service implementation used for proof of concept is written in Python. You can find that here. It's also beneficial because you can take down or bring up services without the need to restart the bot or implement a complicated hot pluggable core. Services that crash also don't run the risk of taking everything else down with it.
Installation and whatnot
Building
Current supported Go version is 1.7. All packages are vendored with Godep and stored in the repository. I update these occasionally. Make sure you have a functioning Go 1.7 environment.
Install ZeroMQ4 (reference your OSs package install documentation) and make sure libzmq exists on the system. go get github.com/kyleterry/tenyks cd ${GOPATH}/src/github.com/kyleterry/tenyks make - this will run tests and build sudo make install - otherwise you can find it in ./bin/tenyks cp config.json.example config.json Edit config.json to your liking. Uninstall
Why would you ever want to do that?
cd ${GOPATH}/src/github.com/kyleterry/tenyks sudo make uninstall Docker
There is a Docker image on Docker hub called kyleterry/tenyks. No configuration is available in the image so you need to use it as a base image. You can pass your own configuration in like so:
FROM kyleterry/tenyks:latest COPY my-config.json /etc/tenyks/config.json Then you can build your image: docker build -t myuser/tenyks . and run it with: docker run -d -P --name tenyks myuser/tenyks.
Binary Release
You can find binary builds on bintray.
I cross compile for Linux {arm,386,amd64} and Darwin {386,amd64}.
Configuration
Configuration is just json. The included example contains everything you need to get started. You just need to swap out the server information.
cp config.json.example ${HOME}/tenyks-config.json Running
tenyks ${HOME}/tenyks-config.json
If a config file is excluded when running, Tenyks will look for configuration in /etc/tenyks/config.json first, then ${HOME}/.config/tenyks/config.json then it will give up. These are defined in tenyks/tenyks.go and added with ConfigSearch.AddPath(). If you feel more paths should be searched, please feel free to add it and submit a pull request.
Vagrant
If you want to play right fucking now, you can just use vagrant: vagrant up and then vagrant ssh. Tenyks should be built and available in your $PATH. There is also an IRC server running you can connect to server on 192.168.33.66 with your IRC client.
Just run tenyks & && disown from the vagrant box and start playing.
Testing
I'm a horrible person. There aren't tests yet. I'll get right on this.... There are only a few tests.
Builtins
Tenyks comes with very few commands that the core responds to directly. You can get a list of services and get help for those services.
tenyks: !services will list services that have registered with the bot through the service registration API..
tenyks: !help will show a quick help menu of all the commands available to tenyks.
tenyks: !help servicename will ask the service to sent their help message to the user.
Services
Libraries
tenyksservice (Python) quasar (Go) To Services
Example JSON payload sent to services:
{ "target":"#tenyks", "command":"PRIVMSG", "mask":"unaffiliated/vhost-", "direct":true, "nick":"vhost-", "host":"unaffiliated/vhost-", "full_message":":vhost-!~vhost@unaffiliated/vhost- PRIVMSG #tenyks :tenyks-demo: weather 97217", "user":"~vhost", "from_channel":true, "connection":"freenode", "payload":"weather 97217", "meta":{ "name":"Tenyks", "version":"1.0" } } To Tenyks for IRC
Example JSON response from a service to Tenyks destined for IRC
{ "target":"#tenyks", "command":"PRIVMSG", "from_channel":true, "connection":"freenode", "payload":"Portland, OR is 63.4 F (17.4 C) and Overcast; windchill is NA; winds are Calm", "meta":{ "name":"TenyksWunderground", "version":"1.1" } } Service Registration
Registering your service with the bot will let people ask Tenyks which services are online and available for use. Registering is not requires; anything listening on the pubsub channel can respond without registration.
Each service should have a unique UUID set in it's REGISTER message. An example of a valid register message is below:
{ "command":"REGISTER", "meta":{ "name":"TenyksWunderground", "version":"1.1", "UUID": "uuid4 here", "description": "Fetched weather for someone who asks" } } Service going offline
If the service is shutting down, you should send a BYE message so Tenyks doesn't have to timeout the service after PINGs go unresponsive:
{ "command":"BYE", "meta":{ "name":"TenyksWunderground", "version":"1.1", "UUID": "uuid4 here", "description": "Fetched weather for someone who asks" } } Commands for registration that go to services
Services can register with Tenyks. This will allow you to list the services currently online from the bot. This is not persistent. If you shut down the bot, then all the service UUIDs that were registered go away.
The commands sent to services are:
{ "command": "HELLO", "payload": "!tenyks" } HELLO will tell services that Tenyks has come online and they can register if they want to.
{ "command": "PING", "payload": "!tenyks" } PING will expect services to respond with PONG.
List and Help commands are coming soon.
Lets make a service!
This service is in python and uses the tenyks-service package. You can install that with pip: pip install tenyksservice.
from tenyksservice import TenyksService, run_service, FilterChain class Hello(TenyksService): irc_message_filters = { 'hello': FilterChain([r"^(?i)(hi|hello|sup|hey), I'm (?P<name>(.*))$"], direct_only=False), # This is will respond to /msg tenyks this is private 'private': FilterChain([r"^this is private$"], private_only=True) } def handle_hello(self, data, match): name = match.groupdict()['name'] self.logger.debug('Saying hello to {name}'.format(name=name)) self.send('How are you {name}?!'.format(name=name), data) def handle_private(self, data, match): self.send('Hello, private message sender', data) def main(): run_service(Hello) if __name__ == '__main__': main() Okay, we need to generate some settings for our new service.
tenyks-service-mkconfig hello >> hello_settings.py Now lets run it: python main.py hello_settings.py
If you now join the channel that tenyks is in and say "tenyks: hello, I'm Alice" then tenyks should respond with "How are you Alice?!".
More Examples
There is a repository with some services on my Github called tenyks-contrib. These are all using the older tenyksclient class and will probably work out of the box with Tenyks. I'm going to work on moving them to the newer tenyks-service class.
A good example of something more dynamic is the Weather service.
0 downloads
(0 reviews)0 comments
Submitted
-

irc3
A pluggable irc client library based on python's asyncio.
Requires python 3.5+
Python 2 is no longer supported, but if you don't have a choice you can use an older version:
$ pip install "irc3<0.9" Source: https://github.com/gawel/irc3/
Docs: https://irc3.readthedocs.io/
Irc: irc://irc.freenode.net/irc3 (www)
I've spent hours writing this software, with love. Please consider tipping if you like it:
BTC: 1PruQAwByDndFZ7vTeJhyWefAghaZx9RZg
ETH: 0xb6418036d8E06c60C4D91c17d72Df6e1e5b15CE6
LTC: LY6CdZcDbxnBX9GFBJ45TqVj8NykBBqsmT
0 downloads
(0 reviews)0 comments
Submitted
-

Limnoria
Limnoria is a multipurpose Python IRC bot, designed for flexibility and robustness, while being easy to install, set up, and maintain.
It aims to be an adequate replacement for most existing IRC bots. It includes a very flexible and powerful ACL system for controlling access to commands, an equality powerful configuration system to customize your bot, as well as more than 60 builtin plugins providing around 400 actual commands.
There are also dozens of third-party plugins written by dozens of independent developers, and it is very easy to write your own with only basic knowledge of Python.
It is the successor of Supybot since 2010 and provides many new features, but keeps full compatibility with existing configurations and plugins.
Support
Documentation
If this is your first install, there is an install guide. You will probably be pointed to it if you ask on IRC how to install Limnoria. TL;DR version:
sudo apt-get install python3 python3-pip python3-wheel pip3 install --user limnoria # You might need to add $HOME/.local/bin to your PATH supybot-wizard There is extensive documentation at docs.limnoria.net and at Gribble wiki. We took the time to write it; you should take the time to read it.
IRC channels
In English
If you have any trouble, feel free to swing by #limnoria on Libera.Chat and ask questions. We'll be happy to help wherever we can. And by all means, if you find anything hard to understand or think you know of a better way to do something, please post it on the issue tracker so we can improve the bot!
In Other languages
Only in French at the moment, located at #limnoria-fr on Libera.Chat.
0 downloads
(0 reviews)0 comments
Submitted
-

sopel
Introduction
Sopel is a simple, lightweight, open source, easy-to-use IRC Utility bot, written in Python. It's designed to be easy to use, run and extend.
Installation
Latest stable release
On most systems where you can run Python, the best way to install Sopel is to install pip and then pip install sopel.
Arch users can install the sopel package from the [community] repository, though new versions might take slightly longer to become available.
Failing both of those options, you can grab the latest tarball from GitHub and follow the steps for installing from the latest source below.
Latest source
First, either clone the repository with git clone git://github.com/sopel-irc/sopel.git or download a tarball from GitHub.
Note: Sopel requires Python 3.7+ to run.
In the source directory (whether cloned or from the tarball) run pip install -e .. You can then run sopel to configure and start the bot.
Database support
Sopel leverages SQLAlchemy to support the following database types: SQLite, MySQL, PostgreSQL, MSSQL, Oracle, Firebird, and Sybase. By default Sopel will use a SQLite database in the current configuration directory, but alternative databases can be configured with the following config options: db_type, db_filename (SQLite only), db_driver, db_user, db_pass, db_host, db_port, and db_name. You will need to manually install any packages (system or pip) needed to make your chosen database work.
Note: Plugins not updated since Sopel 7.0 was released might have problems with database types other than SQLite (but many will work just fine).
Adding plugins
The easiest place to put new plugins is in ~/.sopel/plugins. Some newer plugins are installable as packages; search PyPI for these. Many more plugins written by other users can be found using your favorite search engine.
Some older, unmaintained plugins are available in the sopel-extras repository, but of course you can also write your own. A tutorial for creating new plugins is available on Sopel's website. API documentation can be found online at https://sopel.chat/docs/, or you can create a local version by running make docs.
Further documentation
The official website includes such valuable information as a full listing of built-in commands, tutorials, API documentation, and other usage information.
Questions?
Join us in #sopel on Libera Chat.
Donations
We're thrilled that you want to support the project!
You can sponsor Sopel here on GitHub or donate through Open Collective.
Any donations received will be used to cover infrastructure costs, such as our domain name and hosting services. Our main project site is easily hosted by Netlify, but we are considering building a few new features that would require more than static hosting. All project-related expenses are tracked on our Open Collective profile, for transparency.
0 downloads
(0 reviews)0 comments
Submitted
-
Download Statistics

